Lamina has been, in many ways, the programmatic equivalent of me thinking out loud about asynchronous workflows. A lot of code has been written, built upon, and then discarded in favor of a new, promising line of exploration. Some ideas never survived first contact with implementation, but others have proven more resilient. While I don’t have any illusions of having “solved” the inherent difficulties of the event-driven model, I do think there has been a convergence towards a local maximum in the design space.
But as a result of this blind walk, the implementation of the latest stable release is far from focused. It’s easy enough to modify, but is not a minimal expression of the existing semantics. It’s also not nearly as fast as it could be.
This is why two and a half months ago I announced I was undertaking a performance-oriented rewrite of Lamina. Yesterday I tagged 0.5.0-alpha1, which is a feature-complete rewrite that is one to two orders of magnitude faster across a wide variety of benchmarks.
-
I began by taking the fundamental abstractions, which were built using Clojure’s data structures and concurrency primitives, and implementing them as bare concurrency primitives in their own right. Everything was extensively benchmarked using Hugo Duncan’s excellent Criterium library, which should be much more widely used.
One thing I quickly discovered is that a transactional queue is about ten times slower than an equivalent implementation using ConcurrentLinkedQueues. For this reason, the one significant change to in this latest version is that channel queues are no longer transactional by default.
This is a big enough change that it deserves some explanation. While compatibility with Clojure’s concurrency primitives is very important, in practice transactions don’t seem to be often used in the same applications that use channels. Changing to non-transactional by default gives us an order of magnitude improvement without any visible changes to most or all real-world uses of Lamina.
This is analogous to the changes to primitive numbers in Clojure 1.3, which greatly improves Clojure’s potential performance at the expense of a largely hypothetical use-case. However, this change was mostly a non-issue because BigIntegers are contagious, allowing the change of a single value to affect all other derived values.
Luckily, we can do the same for a channel’s transactionality, because:
channels are graphs
When we chain together channel operators, like
(->> ch (map* inc) (filter* even?))
we’re creating an implicit graph. Each callback triggers subsequent callbacks, possibly applying a transform or predicate, until the value comes to rest in a queue or terminal callback.
This graph, though, is completely opaque to us. All we know is that a series of functions will be called, and that if the chain of operators is long our stack trace can get pretty noisy. Given a long enough chain of operators, we might even get a stack overflow.
In the 0.5.0 codebase, this graph is explicit: channels are implemented as nodes in a graph with a dynamic, thread-safe topology. This has a lot of nice properties:
- the code is simpler
- all nodes derived from a transactional channel will be automatically transactional, and if a transactional channel is fed into an existing network of nodes, it will “contaminate” everything downstream of it
- message propagation along non-branching paths is tail-recursive (and, incidentally, quite fast)
As a fun bonus, there’s even a lamina.viz namespace that lets you use Graphviz at the REPL to visualize the structure
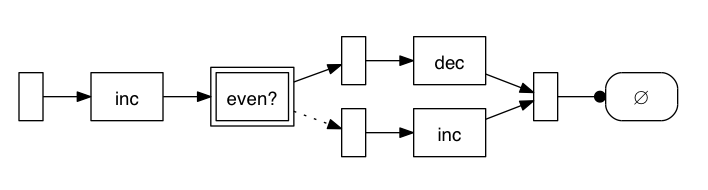
or to see how messages propagate
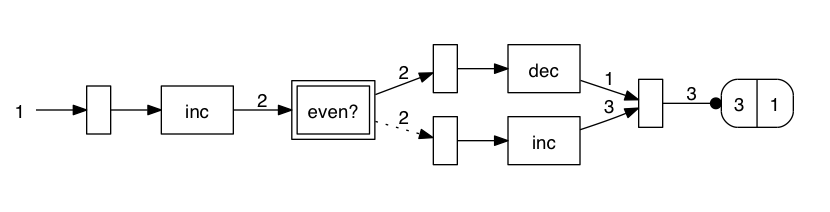
There are a lot of interesting possibilities that fall out of being able to walk and visualize the graph, and these are just hints of what’s possible. I can’t wait to see what other people come up with.
pipelines are macros
Another large change is that pipelines, which are a way to compose asynchronous values, are now implemented as macros. This should be completely transparent to consumers of the library, but it means that pipelines are significantly faster. By partially unwinding the functions, we can make
(def f (pipeline inc inc inc))
(f 0)
faster than
(def f (comp inc inc inc))
(f 0)
even though in the pipeline we need to check every intermediate value to see if it’s unrealized.
-
There’s some more cool stuff in 0.5.0, but it’s deserving of a post of its own. I encourage anyone whose interest is piqued to give it a spin – documentation is sparse, but the semantics are almost identical to previous releases. If you have any questions, feel free to ask in the Aleph mailing list.