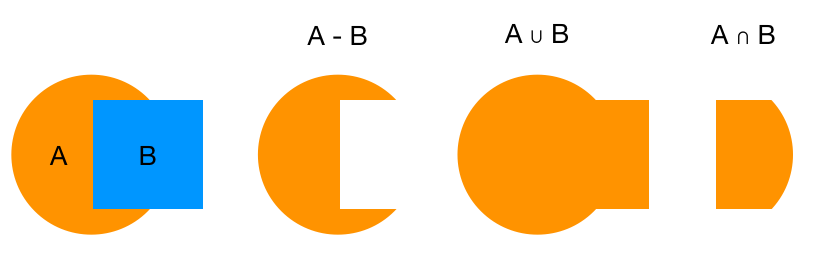
how I spent my summer
A few months ago, I decided to implement set operations on curved regions. I had the the canonical textbook on computational geometry, which described approaches for polygons comprised of straight lines, and it seemed like other projects had extended these techniques to parametric curves. I figured it would take a couple of weeks.
Unfortunately, the field of computational geometry embodies a fundamental contradiction. In geometry, the angles of a triangle add up to exactly π radians, and if u is clockwise from v then v must be counter-clockwise from u. Computers, on the other hand, use floating point representations which make a mockery of these simple Euclidean truths.
The academic literature largely ignores this. Algorithms are proven to be geometrically sound, and robust implementations are left as an exercise for the reader. This is akin to a world in which hash collisions caused unavoidable data loss, and the academic response was to implicitly assume the existence of a perfect hash function. If a paper is predicated on unrealistic assumptions, we cannot evaluate it on its own terms; we must understand, empirically, how well it functions when these assumptions are broken.
With this in mind, we can now look at the existing algorithms for polygon clipping, which is the term of art for polygon set operations. Every technique is a variation on a common theme:
- Given two or more rings, find every point of intersection
- Segment the rings at the points of intersection
- Decide whether each segment should be included, based on the operation being performed
The dozen or so papers on this subject differ only in the third step. Since our decision to include a segment typically inverts at an intersection point, they describe a variety of approaches for using our decision to about one segment to inform our decision about adjacent segments.
My textbook described a method using doubly-connected edge lists, which is a generic geometric data structure. I assumed that meant it could be reused for other problems, so I started my implementation.
A month went by.
I had finished the implementation my first week, but it wasn’t reliable. A DCEL is a collection of linked loops, which can be incrementally updated. When performing a set operation, we incrementally bisect the original set of loops, and then determine which should and shouldn’t be included. Despite my best efforts, I kept finding new shapes that caused adjacent faces to get tangled together, creating a Möbius strip that is simultaneously inside and outside the expected result.
Slowly, I realized the problem wasn’t the data structure, it was the first step that every paper glossed over: finding all the intersections. The DCEL assumes the edges at a vertex have a total ordering: the previous edge is directly clockwise, and the next one is directly counter-clockwise. If we miss an intersection, we might conclude two curves are both clockwise relative to the other, causing everything to fall apart.
I began to look for better ways to find intersections, hoping that if I found an approach that was sufficiently accurate, my work on the DCEL could be salvaged. Unfortunately, the approaches I found in the literature and implemented in the wild were no better than what I had been using. My data structure demanded precise inputs, without internal contradictions, and I couldn’t deliver.
At that point, I began to wonder if I had missed something fundamental. I thought maybe if I dissected how other, more mature, libraries handled my pathological shapes, I could work backwards to see where I had gone wrong. But when I began to feed these shapes into well-established projects like paper.js, I found they failed just as badly.
To find my pathological inputs, I had been using property-based testing. Given a random combination of shapes, I would perform a point-in-region test and compare it to a reference result, generated by querying each shape individually and combining the results according to the operation. Most inputs worked fine, but after a few hundred thousand inputs it would inevitably find some failure.
Other projects, it turned out, had been a little less eager to find their own failure modes. Some only had a handful of example-based tests, others had a static suite of a few thousand inputs they used to validate their changes. If I had missed something, it appeared to be that no one else expected these operations to be particularly robust.
why is this so hard?
Floating point arithmetic is best understood through a simple, maddening fact: a + (b - a) does not necessarily equal b. It might be equal, or it might be off by just a little, where “little” is relative to the larger of the two numbers. This means that when we compare two floating point numbers, we cannot do a precise comparison, we have to ask whether they differ by less than some epsilon value.
This epsilon represents the level of numerical uncertainty to which we’ve resigned ourselves. There is vast folk wisdom around how to minimize this uncertainty, but the fact remains that every arithmetic operation injects a bit of uncertainty, and it grows cumulatively with each successive operation. When dealing with small numbers, this uncertainty may dwarf the values themselves.
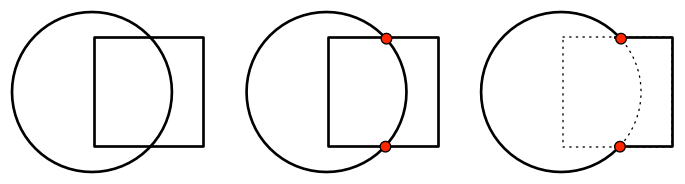
An intersection, in a precise mathematical sense, occurs wherever the distance between the curves is exactly zero:

But in a practical sense, it is wherever the distance between the curves is close enough to zero:

This has at least one intersection, but we could just as easily return three or ten within that overlapping range. This uncertainty is anathema to the published techniques, which rely on counting these intersections to determine whether we’re inside or outside the other shape. A single spurious intersection may cause the entire result to vanish. If two objects with similar curvature move across each other, the result will tend to flicker in and out of existence.
These techniques may suffice for straight lines, which require smaller epsilons, but they are wholly unsuited to the relative imprecision of parametric curves.
embracing the uncertainty
As the weeks passed, the errors uncovered by my tests went from feeling random to feeling malicious. Floating point arithmetic may be deterministic, but as I watched my screen, waiting for the tests to fail, I imagined a demon in the FPU nudging the values as they flowed past, trying to move them beyond the threshold of self-consistency.
One day, I realized this was exactly the narrative behind error-correcting codes; we assume our data has been randomly altered en route, and we want to return it to a consistent state. It didn’t seem like I could get it right the first time, so why not just fix it afterwards?
Consider the union of two ellipses:
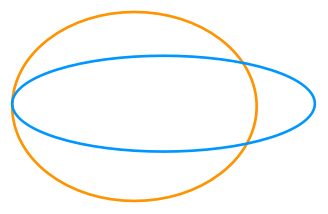
Ostensibly, there should only be three points of intersection, one on the left and two on the right. But for the reasons described above, any intersection routine will likely find multiple points of intersection on the left as the curves converge on each other:
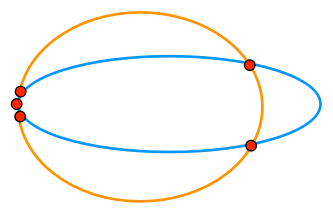
The segments on the left are small enough, and thus imprecise enough, that our spatial intuition for the problem will just mislead us. For this reason, it’s better to think of it as a graph:
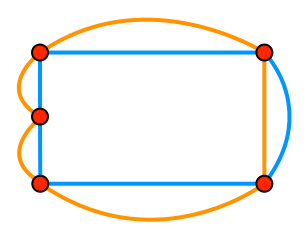
Now we have to decide which edges to include, and which to exclude. Since we’re trying to find the union, we want to keep any segments that are outside the other shape:
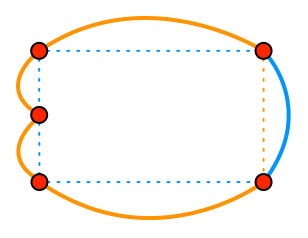
This is a well-formed result; there is a single cycle, and once we remove that cycle there are no leftover edges. But we can’t rely on getting this lucky; the edges on the left might have succumbed to floating point error and believed they were both inside the other:
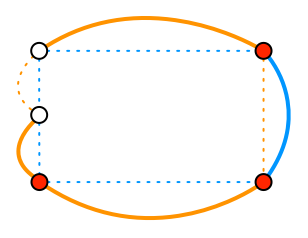
This is not a well-formed result; there are no cycles, and a bunch of leftover edges. To make this consistent, we need to either close the loop, or remove the leftovers. The cost of these changes is measured by the aggregate length of the edges we are adding or removing.
The minimal set of changes is equivalent to the shortest path between the dangling vertices. Having found the path, we then invert the inclusion of every edge it passes through. In this case, it passes through one of the edges we originally excluded, so we add that edge back in, and return the cycle we just created.
Alternately, both edges might think they are outside the other:
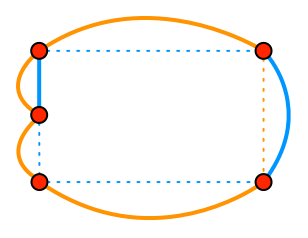
In this case, we have a complete cycle, but once we’ve extracted it there’s a single leftover edge:
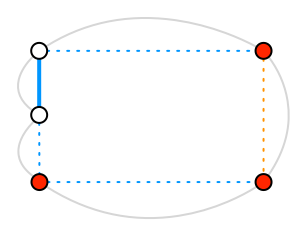
Here again, we search through all the remaining edges for the shortest path between the two dangling vertices. Since it passes through our leftover edge, we remove it.
Every floating point inconsistency will surface as one of these two cases, or some combination thereof. By searching for the shortest path between the dangling edges, we find the smallest possible edit that will yield a consistent result. Of course, a consistent result is not necessarily the correct one, but the fact that floating point errors tend to cluster around the smallest edges makes this a reasonable heuristic. More importantly, it has weathered tens of millions of generative test cases without any issues.
A complete implementation of this algorithm can be found here.
I’m not sure if this is a novel approach, but at the very least it represents a meaningful improvement on the state of the art in open source. Intuitively, it feels like this might be a means to avoid epsilon hell in a wide range of geometric and numerical algorithms. If anyone is aware of prior art in this vein, I’d be very interested to see it.
My work on the Artifex library is ongoing, but I hope it proves useful to others, and look forward to sharing my own projects that it will enable in the near future.
Thanks to Alex Engelberg, Elana Hashman, Angus Fletcher, Reid McKenzie, and Zack Maril for feedback on early drafts of this post.